You shipped faster—why does the codebase feel shakier?
You merge more PRs in a week than you used to in a sprint. The roadmap looks healthier, but on-call gets noisier and “small changes” start breaking things you didn’t touch.
AI-assisted coding can hide the cost of speed. It tends to generate locally correct solutions that don’t match your team’s patterns, skip the edge cases your system learned the hard way, and add new dependencies because that’s the quickest path to “working.” If the tool isn’t anchored to your architecture and conventions, you end up with five ways to do the same thing and tests that don’t cover the risky seams.
The hard part isn’t banning the tools—it’s noticing what kind of debt they add and deciding what to pay down before it hits production.
The new kinds of debt AI quietly adds
That “kind of debt” often shows up in places that don’t fail during a quick PR review. You’ll see three endpoints that validate the same payload three different ways, two retry strategies for the same downstream call, or a new wrapper library pulled in because it made a snippet compile. Nothing is “wrong” in isolation, but the system stops behaving like one system.
AI tends to add pattern debt: more variation in how common tasks get done, which makes future work slower because every change starts with “which version is this?” It also adds integration debt: brittle glue code between services, queues, and SDKs that passes today’s happy path but breaks on timeouts, rate limits, and partial failures. And it adds knowledge debt: code that no one can confidently own because it was assembled faster than it was understood.
The catch is you usually feel it later—in incident response, not in build time—which is why you need early signals, not vibes.
When ‘it works’ isn’t enough: spotting risk before it hits prod
Early signals look boring: a PR that adds a new client library when you already have one, a handler that skips your shared validation layer, or a “quick retry” loop without backoff or a cap. If it changes how you talk to anything outside the process—databases, queues, third-party APIs—assume risk until proven otherwise. The happy path passes, but the first timeout or partial failure is where the debt shows up.
Make review ask for proof, not confidence. If a change adds a new pattern, require a short note: “Why this pattern, and what’s the team-default alternative?” If it touches an integration seam, require one concrete test that forces the failure mode: rate limit, empty response, slow response, duplicate message. If nobody can name the owner for the new module or config, that’s a release blocker.
This adds time, and some checks will feel “extra” on calm weeks.
Choosing what to fix now vs. tolerate for a quarter

Carrying debt for a quarter is only safe when you can predict how it will fail. A shaky validation helper might slow future work, but a new payment-provider client with a “quick retry” loop can turn one timeout into a pileup. Start triage by asking two questions: “Will this amplify an incident?” and “Will this multiply patterns?” If the answer is yes, fix it now.
Put integration seams in the “pay now” bucket by default: anything that crosses service boundaries, touches credentials, or changes retry/timeout behavior. The same goes for ownership gaps. If you can’t name the person or team that will get paged when it breaks, don’t ship it as-is—either assign an owner or keep it behind a feature flag with a clear rollback. Pattern debt is often “pay later,” but only if you write down the team-default approach and log where you deviated, so you don’t re-litigate it in every PR.
The constraint is time: every cleanup sprint steals from roadmap. Guardrails help because they prevent new “must-pay-now” debt from showing up in the first place.
Guardrails that don’t slow the team to a crawl
That “must-pay-now” debt usually appears when the same risky change keeps slipping through: a new SDK, a one-off retry loop, a config tweak nobody owns. The guardrails that work in practice are the ones that target those repeat offenders, not a blanket set of rules that turns every PR into a debate.
Start by carving out “high-friction surfaces” where AI varies the most: integrations, auth/credentials, retries/timeouts, and shared validation. For those areas, require a short checklist in the PR template and make it binary: used the standard client, used the shared validation, added one failure-mode test, named an owner. If a change can’t meet the checklist quickly, keep it behind a feature flag and ship the safer slice.
What slows teams down is unclear escalation. Pick one weekly “debt sheriff” in rotation to answer, fast, “Is this a new pattern we accept?” The limit: this person becomes a bottleneck if you don’t also document the defaults they’re enforcing.
Clarifying ownership when bots write code and pipelines change themselves
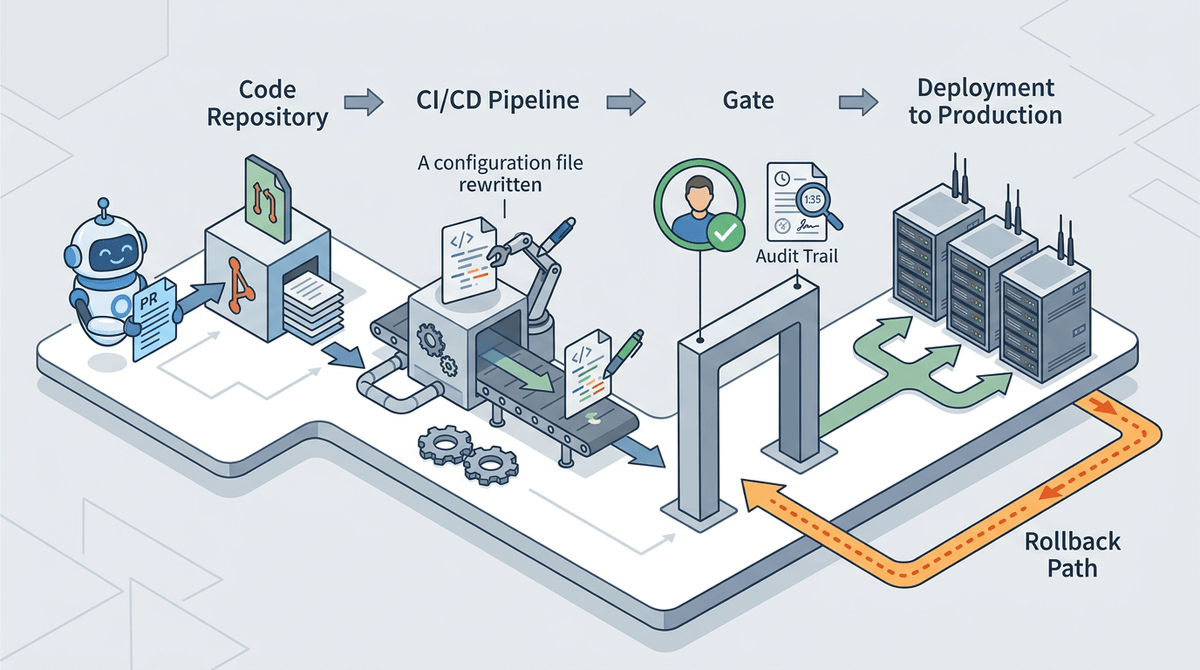
Documenting the defaults helps, but it doesn’t solve the moment when a bot opens a PR, the pipeline rewrites a config, and the on-call engineer asks, “Who owns this?” In most teams, the answer turns into a Slack thread, then a “we’ll figure it out later,” and later becomes an incident with no clear responder.
Make ownership explicit at the seam where change lands. If a generated PR touches retries/timeouts, credentials, or deployment config, require a named human owner in the repo (CODEOWNERS, service catalog entry, or a simple OWNERS file) and a paging target. If a workflow can auto-edit production-affecting files, treat it like a deploy: approvals, audit trail, and a rollback path that’s been tested once, not just assumed.
This can feel bureaucratic on weeks where nothing breaks, and it will slow the first few changes. But once “who gets paged” is non-negotiable, you can turn the debt strategy into a policy leadership will back.
A debt strategy you can explain to leadership—and enforce
Once “who gets paged” is non-negotiable, leadership usually asks the same thing: how do we keep shipping without letting the mess accumulate? Give them a simple scorecard your team can run in minutes: does it touch an integration seam, change retries/timeouts, introduce a new dependency, or create an owner gap. If yes, it’s “pay now” work: block the merge until there’s a failure-mode test, a documented default, and a named owner.
Everything else goes into a capped “debt budget” per sprint—say 10–20%—with a hard rule that debt tickets must name the pattern being standardized and the module being deleted or rewritten. The constraint is real: budget is the first thing that gets raided. Make it visible in sprint reviews, and treat misses like missed roadmap work, not “engineering hygiene.”