Why AI Reliability Matters More Than Accuracy Alone
In a pilot, the demo looks great: the chatbot answers most questions correctly, or the summarizer captures the main points. Then it hits a messy real ticket—missing context, a weird edge case, a policy exception—and it responds with the same confidence as usual. That’s when “accuracy” stops being the right yardstick.
Reliability is whether the system behaves predictably across the situations your team will actually face: it answers when it should, flags uncertainty when it can’t, and stays consistent week to week. A model can score high on a test set and still fail in production because real inputs are noisy and workflows change. The cost shows up fast: rework, bad decisions, and lost trust that’s hard to win back.
To place AI safely, you need a way to tell dependable output from plausible nonsense—and that starts with understanding what “reliable” really means in practice.
Reliable vs Unreliable AI: What’s the Real Difference
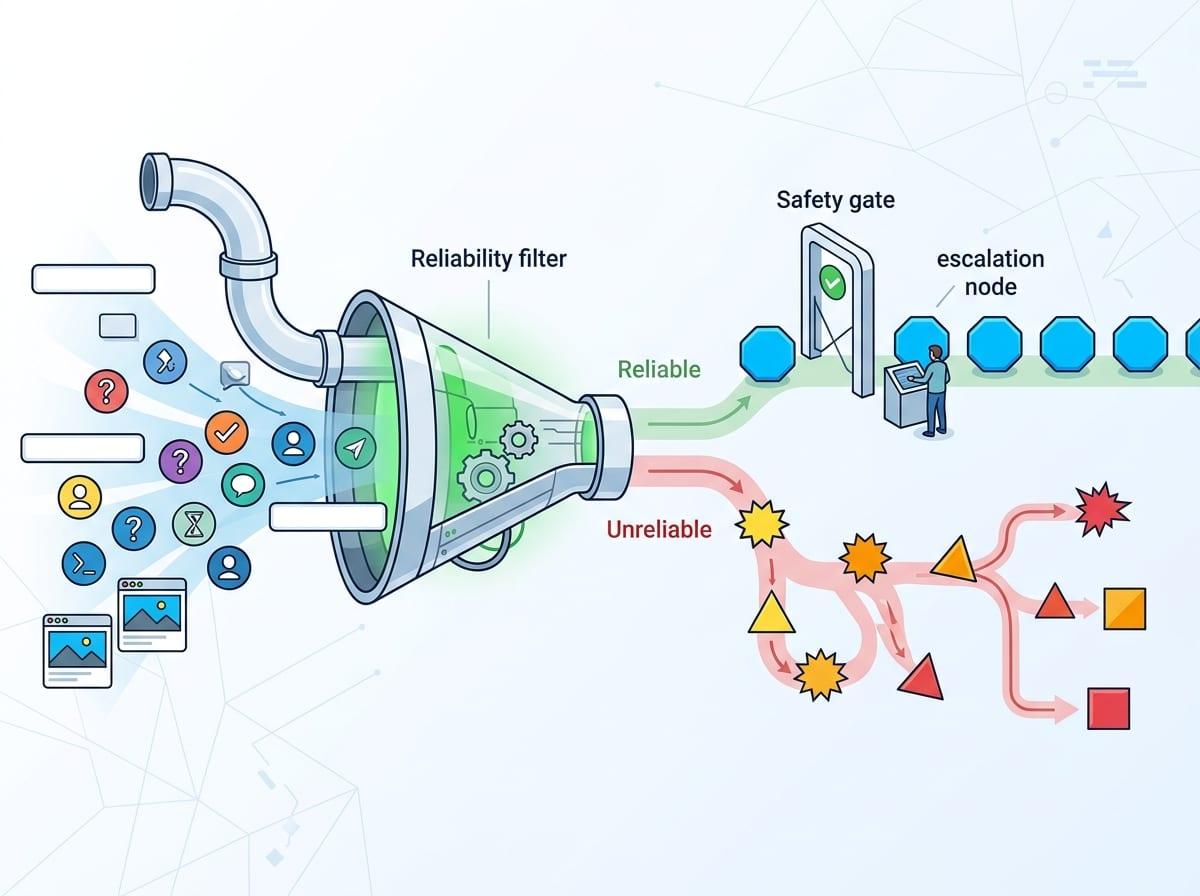
In a real rollout, the difference shows up on the Tuesday when everything is slightly off: a customer pastes a screenshot, a field is blank, or the request mixes two intents. A reliable system stays inside a clear operating lane. It asks for missing details, refuses when the task is ambiguous, or routes to a human when the stakes are high. It also gives similar answers to similar inputs, so your team can build habits around it.
An unreliable system does the opposite: it treats every prompt as solvable, fills gaps with guesses, and changes its mind when you rephrase the same question. The output can look polished, which is what makes it dangerous in decision support or policy-heavy work.
Where Reliability Breaks Down in Real Use Cases
“Safe to act on” usually falls apart the moment the work stops looking like your demo prompts. The first break is input reality: partial tickets, copied-and-pasted chat logs, stale account details, or a screenshot your system can’t read. If the model is forced to guess missing facts, it will often produce a clean answer that sounds decisive, and your workflow may treat that as truth.
The second break is task shape. When the request mixes intents (“refund this order and update the address”) or relies on unwritten policy (“we usually make an exception for VIPs”), the model can’t reliably choose the right path without an explicit rule or a clarifying question. Edge cases then pile on: new product names, uncommon error codes, or a one-off contract clause. You’ll feel it as inconsistency—two agents ask the same thing and get two different recommendations.
Policies change, forms change, customers change their phrasing—and without feedback you can trust, the system won’t fail loudly; it will just get subtly wrong. Most of these failures trace back to the same source: the data the model sees and the data it doesn’t.
The Hidden Role of Data in Creating Unreliable Systems
That “data it doesn’t” is often the quiet reason a system swings from steady to shaky. In production, the model isn’t reacting to your intended workflow; it’s reacting to whatever text, fields, and history you actually pass in. If a ticketing tool drops the last agent note, or your prompt omits the customer’s plan tier, the model will still produce an answer—just anchored to an incomplete picture.
Reliability also breaks when data means different things in different places. A “status” field that sometimes reflects billing and sometimes reflects shipping forces the model to guess which meaning applies. The same goes for messy labels in training examples: “resolved” used for both “fixed” and “customer stopped replying.” You’ll see it as inconsistent recommendations that look like mood swings.
Cleaning logs, aligning fields, and collecting feedback takes time your team didn’t budget, but skipping it sets you up for surprises when the next change rolls out.
Why Even High-Performing Models Can Fail Unexpectedly

Those surprises often land right after a “successful” evaluation: the model looked strong in testing, then it fails on a normal day because the conditions quietly changed. A new policy rolls out, the UI renames a field, or customers start using a new product nickname. If the model learned patterns tied to yesterday’s wording, it can keep sounding confident while its answers slip out of date.
High scores also hide thin coverage. Your test set may be heavy on common cases (“standard refund”), while production is full of mixed, messy ones (“refund plus chargeback plus shipping hold”). The model can do great on the center of the distribution and still collapse at the edges, especially when it must infer missing facts. Even small prompt edits, temperature settings, or retrieval changes can shift outputs enough to break downstream steps like auto-tagging or routing.
The only safe assumption is that performance on a benchmark is not a promise about next month’s workflow.
Signals That an AI System Cannot Be Trusted
That “next month” risk shows up in small warnings your team can spot long before a headline failure. The first is confidence without grounding: the system gives a precise recommendation, but can’t point to the ticket text, policy snippet, or retrieved record it used. If you ask “what did you base that on?” and it restates itself, you’re looking at an answer that may be built on guesses.
Another signal is instability under light pressure. Rephrase the same request, add one missing field, or paste the same case from a different channel, and the output swings from “approve” to “deny.” In operations, that forces agents to game the prompt instead of following a process. You’ll also see brittle behavior around edge details: new SKUs, uncommon error codes, or exceptions like “customer is on a legacy plan.” If those cases trigger confident but wrong steps, you’ve found the boundary of the system’s lane.
Finally, watch for silent drift: rising override rates, more “looks right” summaries with factual mistakes, or teams building side spreadsheets to double-check. Once those workarounds appear, you need guardrails—not another demo.
How to Build and Evaluate Trustworthy AI Systems
Guardrails start by writing down the lane: what inputs are required, which outcomes are allowed, and when it must refuse or hand off. If the tool can’t access the right fields (plan tier, policy version, account history), don’t let it “fill in” and still trigger actions like refunds or account changes.
Evaluate it the way work actually arrives. Build a small test pack of messy tickets, mixed intents, missing fields, and edge policies, then check for three things: stable answers across rephrases, grounded citations to the record or policy, and sensible “I can’t tell” behavior.
Ship with oversight: sampling, override tracking, and a feedback loop tied to real outcomes. It takes time—someone must review failures and update prompts, retrieval, or data—or drift will win.











