When the model ships and the product starts “moving back”
You ship a model that looks clean in offline metrics, then the live numbers start sliding within days. Click-through spikes, then drops. Fraud blocks shift to new patterns. Prices “work” until competitors and customers react. Nothing is broken in the code. The product changed because the model changed it.
That’s the difference between predicting a system and steering one. A ranker that boosts certain items causes more views, which changes what gets clicked, which changes what looks “popular” in tomorrow’s training data. If you only log what the model showed, you quietly lose evidence about what it didn’t show, and you can’t tell whether the model learned better or just narrowed its world.
Experimentation slows teams down, logging adds cost and latency, and safety review becomes a gate. Before you debate retraining cadence or online updates, you need one clear picture of the loop your product is actually running.
What exactly is the loop in your product right now?
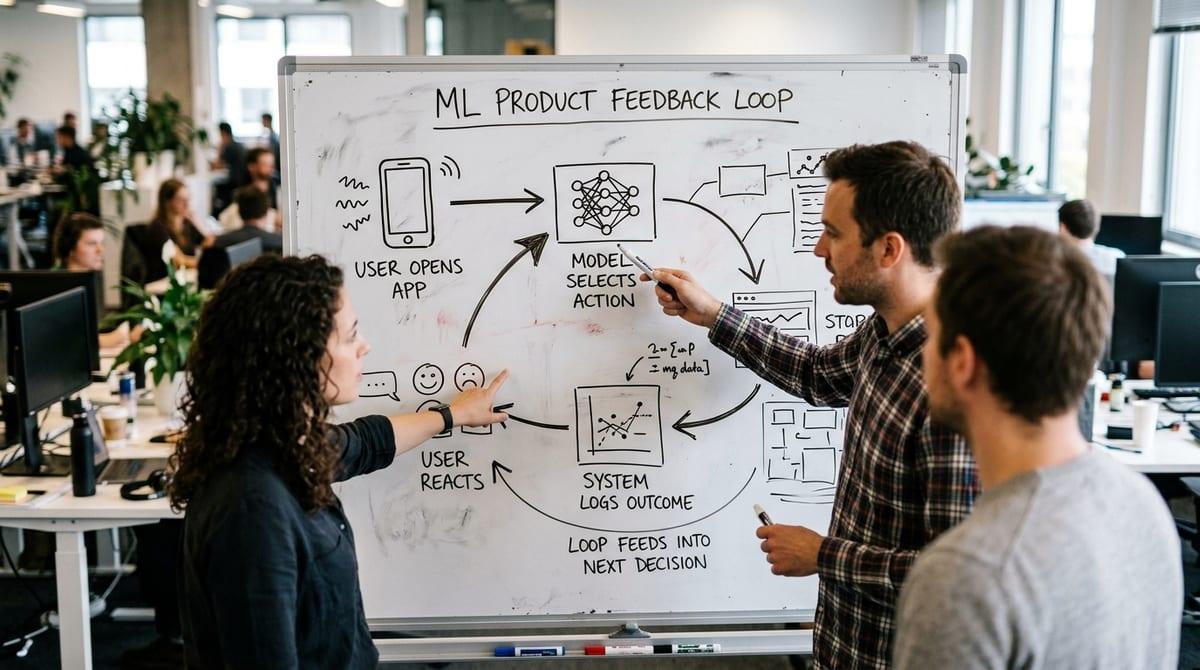
That “one clear picture” usually starts as a messy whiteboard: a user opens the app, the model picks an action, the user reacts, and the product records what happened. The loop is whatever path takes that reaction and turns it into the next model decision. If your ranker trains on clicks, then the loop is “rank → exposure → click → training labels → next rank,” not “rank → click.” The missing step is exposure, and it’s where most surprises hide.
Map it in plain boxes and arrows, then label what you control versus what you only observe. Where do labels come from—explicit ratings, purchases, chargebacks, support tickets, later churn? If a pricing model changes price, and refunds rise two weeks later, that delay is part of the loop. If a fraud rule blocks an account, the attacker adapts, and your “negatives” shift under you.
Choose the smallest set of events that lets you reconstruct exposure, action, and delayed outcomes, because that’s what you’ll need when the loop tightens.
The first week’s surprises: reinforcement, blind spots, and delayed payback
When the loop tightens, the first week often looks “better” before it looks worse. A ranker that rewards clicks can quickly concentrate traffic on a few items, which makes them look even more clickworthy, which concentrates traffic again. If you watch only CTR, it reads like progress. If you also watch diversity, repeat exposure, or seller coverage, you may see the system collapsing into a smaller slice of inventory.
Blind spots show up the moment your logs become self-fulfilling. If you only collect outcomes for what the model chose to show or price, you can’t tell whether the model improved or just stopped exploring. Teams feel this as arguments about causality: “Users don’t want this” versus “we never gave it a chance.”
Then the delayed payback lands. Refunds, chargebacks, churn, and complaint tickets arrive days later, and the model may already have reinforced the behavior that caused them. Adding holdouts, extra logging, or longer attribution windows slows shipping—so you’ll need to be deliberate about what you measure first.
If you can’t observe it, you can’t stabilize it—so what do you instrument?
That deliberation usually collapses into a familiar moment: someone asks, “Is the model getting smarter, or are users just being pushed into narrower choices?” If you can’t answer that from your data, you can’t stabilize anything, because every “improvement” might be a logging artifact.
Start by instrumenting what the model caused to happen: exposure, not just outcomes. Log the candidate set (or at least a stable summary like counts, score percentiles, and key feature buckets), the final action taken (rank/price/block), and the position or treatment intensity. Without this, you can’t separate “users preferred it” from “we only showed it.” For routing or fraud, the equivalent is what options were available, what rule/model fired, and what would have happened under the next-best action (even if estimated).
Then add two clocks: short-loop metrics (CTR, accept rate, immediate revenue) and delayed outcomes (refunds, churn, support contacts) with explicit attribution windows. The real-world pain is storage and latency: detailed candidate logs get expensive fast, so most teams start with sampled logs plus a small always-on holdout to keep a baseline you can still trust.
Choosing a safe experiment when users are part of the system

That always-on holdout is also your safest experiment: it gives you a stable counterfactual while the rest of the product shifts. Start with the smallest change that can move one link in the loop—swap a re-ranker stage, adjust a pricing elasticity cap, or change a fraud threshold—while keeping everything else fixed. If you can’t do that, use a shadow run: score with the new model, log what it would do, but don’t act on it yet.
When you must test live, throttle exposure and add hard guardrails. Use ramp-by-percent with a fast rollback, and cap “treatment intensity” (max price delta, max demotions, max blocks per minute). For rankings, interleaving or small exploration buckets reduce the chance you wipe out inventory coverage before you notice.
Delayed outcomes mean “safe” may require longer windows and more users than your team wants to wait for. Those results determine whether you retrain, update online, or freeze and enforce constraints.
How should the model adapt: retrain, update online, or freeze with guardrails?
Those results usually force a choice: do you want the model to change itself, or do you want changes to happen only when you say so? If delayed outcomes swing wildly (refunds two weeks later, fraud adapting overnight), online updates can chase noise and amplify the loop. In that case, a fixed model plus guardrails is often safer for a while.
Batch retraining works when drift is real but not minute-to-minute. You can widen data windows, rebalance for lost exploration, and re-run backtests with the same attribution window you use in production. The cost is calendar time: if your pipeline takes three days, you’re committing to three days of lag whenever the world shifts.
Online updates fit when you have fast, reliable labels (accept/reject, immediate loss signals) and strong constraints. Put caps on parameter movement, enforce action limits (max price delta, max blocks), and keep a live holdout to detect “learning” that’s just narrowing choices. Once you pick the mode, you need a way to keep it stable while it keeps learning.
Staying stable while you keep learning
That stability usually breaks when teams treat monitoring as a dashboard instead of a control. Keep one always-on baseline: a fixed holdout policy and a frozen evaluation dataset with the same attribution window you use in prod. If the live model improves but the holdout doesn’t, you’re probably watching a loop tighten, not real lift.
Then make change boring. Ship updates behind a ramp, require pre-set stop conditions (refund rate, block appeals, inventory coverage), and run a canary that uses stricter caps than the main rollout. The constraint you’ll hit is operational: delayed outcomes mean your rollback decision may need to wait a week, so plan for “safe but slow” as the default and reserve fast learning for metrics you can trust quickly.
The mental shift is simple: don’t ask “is the model accurate?” Ask “is the system stable under this policy?” That question keeps your learning loop pointed in the right direction.











