You have thumbs‑up data—now what?
You launch a chatbot, add a thumbs‑up/down button, and within a week you’ve got a spreadsheet full of votes. Then the awkward question hits: how does that turn into a model that actually behaves differently, instead of just a dashboard that tells you users are unhappy?
In most products, feedback directly changes a rule or a template. With LLMs, it doesn’t. Those clicks have to be translated into training examples, then into a single “reward” signal the system can optimize, and only then into small updates that nudge outputs in the direction users prefer.
It sounds simple, but it costs time and labeling effort, and it can amplify whoever clicks the most.
What exactly are humans judging (and what they’re not)
In a real feedback queue, most votes aren’t about “truth” in the abstract. They’re about whether the answer fit the moment: did it follow instructions, use the right tone, cite the right policy, and stop when it should. If a support bot refunds when it shouldn’t, a downvote is often a judgment about company rules, not language quality.
That means you’re mainly collecting preferences over outputs, not a clean label like “correct/incorrect.” Raters compare two answers, or score one answer against a checklist, and you treat that as “this style of response is better for this prompt.” What they’re not reliably judging: hidden reasoning, factuality they didn’t verify, or long-tail edge cases they never see. If the prompt requires specialized knowledge, raters will reward confidence and smooth phrasing unless you constrain them with references or tests.
Once you define what “better” means, you can start turning it into something the model can optimize.
Turning preferences into a reward: the hidden model in the middle
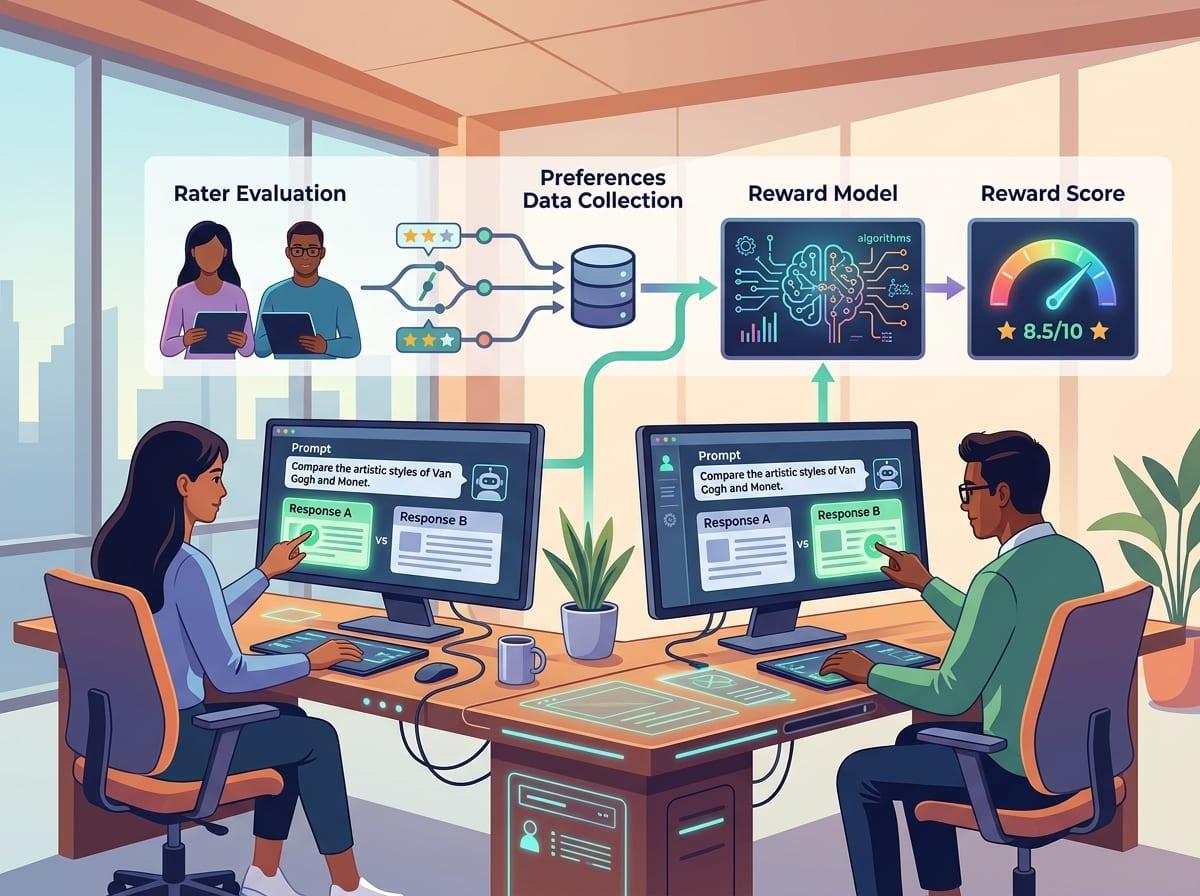
In practice, you don’t feed a pile of thumbs-up directly into the chatbot and expect it to “learn.” You take prompts and multiple candidate answers, then train a separate model—the reward model—to predict which answer a rater would pick. It’s basically a scorer: given the same prompt, it should assign a higher number to the response people preferred, and a lower number to the one they rejected.
This is where messy product reality shows up. If your raters mainly punish long answers, the reward model will learn “short” as a proxy for “good.” If your queue is dominated by one customer segment, it will learn their taste as the default. And if your comparisons are noisy—people click quickly, or guidelines change mid-week—the scorer will bake that confusion in.
Once that scorer works reasonably well, you can use it like an automated judge during training: generate an answer, score it, and push the chatbot toward higher-scoring behavior. The catch is that you’re now optimizing against the scorer’s quirks, not directly against users.
When the model learns: improving behavior without rewriting the whole brain
That’s why training usually adds guardrails around the scorer’s quirks. In a typical loop, you sample prompts, have the chatbot draft answers, run them through the reward model, and treat that score like “points.” Then a reinforcement-learning step updates the chatbot to make higher-scoring answers more likely the next time those kinds of prompts show up.
The key detail: you don’t rewrite the whole model. Most setups push small changes and penalize drifting too far from the original behavior (often by keeping the new answers close to a “reference” version of the model). Practically, that means you can improve things like refusal style, format, and policy-following without losing basic fluency.
But the training can still overfit to what the scorer rewards. If the scorer “likes” cautious, hedged language, you may get safe-but-useless replies. And it’s expensive: you pay for lots of generated samples, plus the compute to update the model. So where do you get enough good feedback to make this worth running?
Where should feedback come from when you’re not a research lab?

Most teams start by pulling feedback from wherever it’s already flowing: support tickets, chat transcripts, escalation notes, and the thumbs-up/down stream. That’s workable if you can tie each rating to the exact prompt, answer, and outcome. If you can’t, you end up training on guesses—like assuming a user who reopened a ticket “disliked” the last reply.
For higher-signal data, borrow your own experts. Support leads, policy owners, or QA reviewers can do a small number of paired comparisons with clear rubrics (“followed refund policy,” “asked one clarifying question,” “used approved tone”). It’s slower than crowdsourcing, but it matches your rules. You can also sample the failures you already pay for: escalations, refunds, compliance flags. Those are rare, so you’ll need to oversample them on purpose.
The hard part is consistency. Guidelines drift, raters get tired, and edge cases spark debates. Lock the rubric, audit a slice weekly, and be ready to pause collection when the rules change.
What goes wrong after you deploy—and how you’ll recognize it
If you don’t pause collection when rules change, you’ll ship a “better” model that suddenly feels worse in production. The first sign is usually a support pattern, not a benchmark: more escalations after “helpful” answers, longer chats that go nowhere, or users asking the same question twice because the bot hedged instead of committing.
A common failure is proxy gaming. If downvotes correlate with long replies, the model learns to be brief, even when the user needs steps. If raters punish uncertainty, it learns confident wording, even when it’s guessing. Watch for response shapes that shift across the board—shorter, more refusals, more disclaimers—because those are reward-model preferences leaking into everything.
Then there’s drift. New product features, new policies, and seasonal user intent change prompts faster than your feedback loop updates. Track a small “canary” set of real tasks weekly and compare outcomes, not just thumbs, before you decide to retrain again.
Choosing RLHF as a product lever (or skipping it)
When a canary set starts slipping, the temptation is to “just do RLHF” and expect a broad fix. It works best when your problem is preference-shaped and repeatable: policy-following, tone, refusal style, asking one clarifying question, or producing a standard format. If the main pain is missing knowledge, stale docs, or tool failures, RLHF mostly teaches the model to sound nicer about being wrong.
Budget for the unglamorous parts: rater time, tight rubrics, sampling the right failures, and ongoing audits when policies change. Also plan for local wins that create global weirdness—like shorter answers everywhere because the scorer learned “brief.” If you can’t sustain that loop, start smaller: improve retrieval, add hard checks, or use targeted supervised examples, then revisit RLHF when the behavior goal is stable.